Paper Review: TradeMaster
Review of NeurIPS-Published “TradeMaster: A Holistic Quantitative Trading Platform Empowered by Reinforcement Learning”
Abstract
Recent advancements in Reinforcement Learning in Financial Trading (RLFT) have improved trading models, but implementing these in real-world markets remains challenging due to the intricate nature. Also, due to alpha decay phenomenon, financial practitioners are not keen to share their source code of their algorithms. The paper underscores the need for an open and comprehensive platform that can manage these complexities effectively. TradeMaster is a open-source platform that offers standardized implementations of a wide range of state-of-the-art RLFT algorithms. The paper was written by AMI team from Nanyang Technological University in Singapore. The code can be found here: Github.
Introduction
TradeMaster serves as a toolkit that supports both empirical benchmark to compare state-of-the-art RLFT algorithms and graphical user interface (GUI), aiming to facilitate transparent and reproducible research and real-world deployment of models in the finance world.
The paper points out three main challenges in RLFT deployment: engineering, benchmarking, and usability. Building a sophisticated RLFT pipelines requires substantial efforts. Considering RLFT is still an immature domain, implementation could be tedious and the performance is heavily context-dependent- making benchmarking difficult. TradeMaster addresses these challenges through its unique design:
- TradeMaster offers itself as a open-source software toolkit that implements the entire RLFT workflow, including real-world financial datasets and popular RLFT algorithms. It additionally supports systematic evaluation of RLFT models and visualization tools to help its users better comprehend their model’s performance in varying complex environments.
- The empirical benchmark component of TradeMaster provides a standardized framework for transparent, fair, and reproducible comparison of RLFT algorithms across various financial contexts and markets.
- The GUI facilitates a practical way of visualize the workflow of TradeMaster. TradeMaster also incorporates advanced AutoML techniques for feature engineering and hyperparameter tuning- significantly improving the usability and accessibility of TradeMaster.
Quantitative Trading as a Markov Decision Process
TradeMaster utilizes Markov Decision Process (MDP) to formulate quantitative trading tasks following a standard reinforcement learning scenario, encompassing state space, action space, reward function, and transition function.
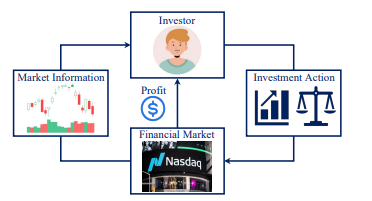
Figure 1: MDP formulation in RLFT
As shown in Figure 1, TradeMaster formulates a scenario detailing an agent (investor) interacting with an environment (the financial markets) in discrete time to make actions (investment decision) and get reward (profits). The paper formally defines the MDP as a 6-tuple: \((S,A,P,R,\gamma,H)\).
Specifically, where \(S\) is the finite set of state, \(A\) is a finite set of actions, \(P=S\times A\times S\rightarrow[0,1]\) is a state transition function, \(R:S\times A\rightarrow\mathbb R\) is the reward function, \(\gamma\in[0,1)\) is the discount factor, and \(H\) is the time horizon indicating the length of the trading period.
A stationary policy \(\pi_\theta:S\times A\rightarrow[0,1]\), parameterized by \(\theta\), assigns each state in \(S\) a distribution over actions where \(a\in A\) has probability \(\pi(a\|s\in S)\).
The goal of the agent is to find the optimal policy that maximizes the expected sum of discounted reward: \(\pi_{\theta ^ *}=argmax_{\pi_\theta}\mathbb E_{\pi_\theta}[\sum^T_{i=0}\gamma^ir_{t+i}\|s_t=s]\). The above representation of the MDP only formulates a general version. Being a holistic platform, TradeMaster can cover a wide range of trading scenarios.
TradeMaster’s Design Principles and Components
TradeMaster is built on three design principles: prioritizing pipeline over algorithms, being minimal and unintrusive, and encouraging extension for new methods. TradeMaster takes a new approach in building a trading platform where the ease of usability comes first. It supports various high-level API functions and enables proper pipelines first while the intricate algorithms run on the back burner.
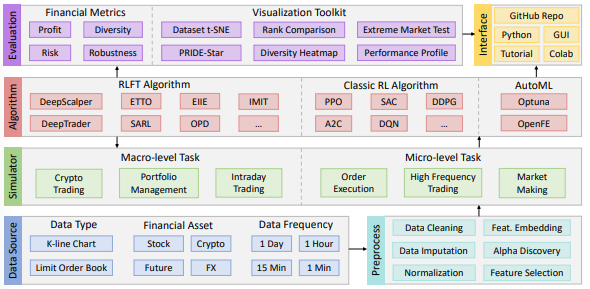
Figure 2: Overview of the TradeMaster platform, which includes six key components for RLFT
TradeMaster includes diverse data sources, efficient preprocessing, realistic market environments, systematic evaluations, and multiple user interfaces. All these components are interlaced within TradeMaster, enabling successful execution of the platform, as shown in Figure 2.
Despite only a tiny fraction of successful reinforcement learning algorithm codes are made public, the state-of-the-art RLFT algorithms being used in TradeMaster are implemented in a standardized way- made available through open-source. TradeMaster also includes 9 other classic reinforcement learning algorithms based on the widely used RLib library for other quantitative trading tasks.
Empirical Benchmarking and Performance Analysis
TradeMaster does an excellent job in simulating various market environments. Evaluating an algorithm specifically in financial setting may heavily depend on its context. Many RLFT seek to isolate gains through “all-else-equal” configurations in experiments, but TradeMaster serves a structured evaluation framework by providing a comprehensive RLFT empirical standard.
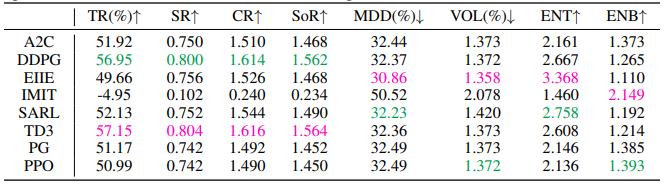
Table 1: Performance comparison (mean of 5 individual runs) on the US stock market of 8 RLFT algorithms in terms of 8 financial metrics. Pink and green indicate best and second best results
Table 1 shows an example of US stock market of 8 RLFT algorithms and compares their performance across 8 different 8 financial metrics.
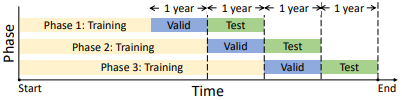
Figure 3: Demonstration of Data Split
TradeMaster splits the training phases into 3 phases. The paper follows the rolling data split paradigm. The code implementation of building environments for train/valid/test looks like this:
args = parse_args()
cfg = Config.fromfile(args.config)
dataset = build_dataset(cfg)
train_env = build_env(cfg, dataset, default_args=dict(..., task="train"))
valid_env = build_env(cfg, dataset, default_args=dict(..., task="valid"))
test_env = build_env(cfg, dataset, default_args=dict(..., task="test"))
![]()
Figure 4: Rank distribution in terms of 4 financial metrics on the US stock market
The paper plots the rank distribution of 8 RLFT methods in terms of Total Return (TR), Sharpe Ratio (SR), volatility (VOL), and Entropy (ENT) across 3 test periods with results of 5 random seeds in each period. The \(i\)-th column in the rank distribution plot shows the probability that a given method is ranked at \(i\)-th place in the corresponding metrics. For Figure 4, the example shows that TD3 slightly outperforms DDPG for TR and SR.
Extreme Market Conditions
The paper further test its platform’s risk-control and reliability by picking one extreme market period with black swan events. For example, September 1-30 in 2021 was a volatile time for the US stock market due to concerns over interest rate increase and the congressional shutdown caused by COVID-19.
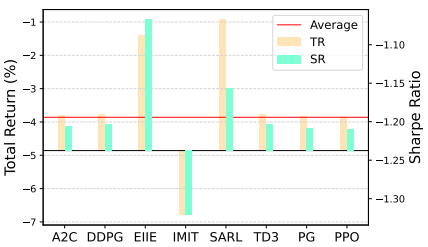
Figure 5: Performance of RLFT methods during extreme market conditions
Figure 5 plots the TR and SR during the period of extreme market conditions- where the red line indicates market average. Most reinforcement learning methods achieves similar performance as they tend to be conservative during extreme market conditions. However, more radical methods like EIIE and SARL shows that they are more suitable options.
TradeMaster as a User Interface
TradeMaster provides a very intuitive Python library and user interface. Extending from the previous code snippet:
# Setup Network and Optimizer
net = build_net(cfg.act)
optimizer = build_optimizer(cfg, default_args=dict(…))
The action that usually follows after building the environment is building the network and the optimizer for the chosen reinforcement learning algorithm like the above example.
# Setup Loss and Transition Function
criterion = build_loss(cfg)
transition = build_transition(cfg)
The above code snippet continues to build the model by setting up the loss and transition functions for the model. The functions are not complex to call or understand, and is quite easy to use.
# Build Reinforcement Learning Agent
agent = build_agent(cfg,default_args=dict(…))
# Build Trainer Based on Environments
trainer = build_trainer(cfg,default_args=dict(train_env=train_env, valid_env=valid_env, test_env=test_env, agent=agent))
# The Procedure of Training and Validation
trainer.train_and_valid()
# The Procedure of Testing
trainer.test()
# Build Reinforcement Learning Agent
agent = build_agent(cfg,default_args=dict(…))
# Plot
plot(trainer.test_environment.save_asset_memory(),alg="MODEL-NAME LIKE: DeepScalper")
After loading the configuration file and setting up the network and optimizer, and loss function, TradeMaster builds reinforcement learning agents and trainer. Then it proceeds to call train, valid, and test functions to evaluate the performance of reinforcement learning agents across various financial metrics.
Discussion
A few of the biggest takeaways from TradeMaster is their standardized implementations of the reinforcement learning algorithms and being able to access their platform through Github- allowing its users to build their own version of TradeMaster based on their personal needs.

Table 2: Comparison of TradeMaster and existing trading platforms. # indicates “the number of”
The fact that it is a pioneer in reinforcement learning trading platform like no-other, bridges the gap between reinforcement learning in finance in academic research and real-world deployment. As shown in Table 2, TradeMaster includes an extensive amounts of functionalities that other previous platforms lack.
TradeMaster is seen as a catalyst for the development of the RLFT domain. For researchers, they can rapidly implement and evaluate their own methods on an already-established platform so they can focus on science than engineering solutions, and for investors, they can have a taste of reinforcement learning-based trading methods without in-depth knowledge of AI and coding. Additionally, investment firms can use TradeMaster as a code base to enhance their legacy trading systems with reinforcement learning techniques. Deducing from its potential impacts, it would be safe to assume that TradeMaster will facilitate advanced reinforcement learning techniques in trading systems and encourage interdisciplinary research between finance and AI.